- Galego
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Programación de FPGAs de Xilinx e fluxo de deseño de Vivado explicados
Catálogo

Explorando os tutoriais de FPGA de Xilinx
Traballar con FPGAs pode parecer mentalmente máis pesado ca o software ao principio, en parte porque o obxectivo non é executar instruccións senón describir estruturas de hardware que funcionen ao mesmo tempo. Terminas pensando na concorrencia, nas regras de reloxo, no comportamento de restablecemento e en se os informes de temporización coinciden co que pensaches que construíches. Cando as persoas se frustran ao comezo, non é xeralmente porque lles falte esforzo, senón porque demasiadas pezas móbiles cambian entre os intentos e a causa do fracaso se fai incómoda e escorregadiza.
Un camiño sólido é repetir o mesmo fluxo de traballo ata que se converta en familiar o suficientemente para que os erros se destaquen. Mantén unha placa de Xilinx ben soportada no teu escritorio, comeza cun pequeno deseño HDL, simúlao ata que as formas de onda teñan sentido, executa a síntese e a implementación en Vivado, programa o dispositivo e logo confirma o comportamento en pinos reais. Aínda que este proceso poida parecer repetitivo, axuda a reducir a incerteza sobre se un problema é causado polo código de deseño, as restricións ou a configuración da placa, facendo que a depuración sexa máis eficiente.
Na aprendizaxe día a día, a parte empinada da curva costumiza agrupase arredor de poucas habilidades que se reforzan entre si: usar o flujo de Vivado con disciplina, escribir Verilog sintetizable que mapee da forma que esperas e depurar os inevitables buracos entre a simulación e a placa física cun método no que confías. Se tratas cada construción como un experimento controlado, cambias unha variable, observas o efecto e anotas o que viste, notarás que pasas menos tempo adiviñando e máis tempo formando instintos fiables.
Usa o fluxo de proxecto de Vivado dunha maneira que se manteña estable co tempo
Vivado comportase menos como un simple botón de compilar e máis como un pipeline que converte RTL nun deseño situado e enroutado que debe vivir dentro das realidades eléctricas e de temporización da placa. Moitos principiantes descubren, ás veces de forma dura, que moita corrección vive fora do HDL: as restricións, as definicións de reloxo, os estándares de I/O e os axustes de ferramentas poden decidir silenciosamente se o hardware se comporta da forma que a simulación prometeu.
Un fluxo limpo comeza mantendo a configuración do proxecto modesta e repetible, para que poidas dicir cando realmente melloraches o deseño fronte a cando cambiaches accidentalmente o entorno.
Escolla unha placa soportada e mantente nela o suficiente para construír a intuición que podes reutilizar. As placas cunha documentación sólida e deseños de referencia tendan a reducir a ansiedade de fondo, porque podes comprobar a túa distribución de pinos, reloxs e supostos de enerxía sen ter que buscar publicacións en foros non oficiais.
Comeza cun módulo superior que produza un resultado visible rápidamente. Esa retroalimentación inmediata axúdache a validar que o reloxo está a funcionar, que os pinos están mapeados correctamente e que os bitstreams se están xerando como pensabas.
Exemplos de comportamento observable a nivel superior:
• Un LED que parpadea
• Un eco UART
• Un contador que acende GPIO
Un hábito práctico é estandarizar un pequeno modelo de nivel superior desde o principio. Por exemplo, mantén unha entrada de reloxo, un enfoque de reinicio que entiendas e un pequeno conxunto consistente de GPIO. Cando a estrutura se mantén igual de proxecto a proxecto, podes centrar a túa atención na nova lóxica en vez de re-derivar fundamentos cada vez, algo que pode resultar tedioso e sorprendentemente propenso a erros.
As restricións son unha parte fundamental do deseño de FPGA en lugar de ser un passo final de axuste. Moitos problemas de hardware temperá ocorren incluso cando o deseño RTL é correcto porque faltan ou son incorrectas as restricións do reloxo, os pinos están asignados incorrectamente ou os estándares de I/O non coinciden cos requisitos reais da placa.
Un fluxo de traballo concreto que che mantén honesto é definir reloxs en XDC, mapear portas utilizando o XDC mestre do fornecedor como referencia e logo verificar os estándares de I/O contra o esquema da placa. Ese proceso pode parecer un pouco burocrático ao principio, pero tende a sustituír a sospeita vaga por feitos verificables.
O peche de tempadas non está reservado só para deseños rápidos. Mesmo a lóxica que parece lenta sobre o papel pode comportarse mal se a ferramenta infere relacións de reloxo non intencionadas ou se as señales asíncronas son tratadas de maneira casual. Sentirse cómodo lendo informes de temporización cedo pode reducir esa incómoda sensación de "Espero que isto estea ben" cando os deseños se fan máis grandes.
Vivado está constantemente dándoche a súa opinión sobre o teu deseño; a parte dolorosa é que é fácil pasar ads avenios e logo pasar horas depurando un problema que xa estaba descrito na consola. Co tempo, as persoas que se moven máis rápido son a miúdo aquelas que establecen un hábito tranquilo de revisar informes após cada execución, mesmo cando esperan que todo esté ben.
Despois de cada execución de síntese/implementación, mantén estas categorías de informes xuntas na súa propia liña de lista de verificación:
• Estado de temporización e camiños críticos
• Utilización de recursos (LUT/FF/BRAM/DSP) en comparación coas expectativas
• Resultados de inferencia (para RAMs, bloques DSP e outras estruturas pretendidas)
Cando unha advertencia está presente desde a primeira compilación, tende a seguir aparecendo nas fallas máis estranas máis tarde. Una postura produtiva é asumir que as advertencias merecen atención até que poidas explicar, en termos de enxeñaría sinxela, por que son benígnas para o teu deseño específico.
Escribe Verilog sintetizable que mapee limpo sobre o hardware de FPGA
O traballo en HDL está máis preto do deseño de circuítos que do desenvolvimento de aplicacións, e ese cambio pode ser emocionalmente desestabilizador: podes escribir Verilog válido que simula de forma espléndida e, con todo, síntese en algo máis lento, maior ou simplemente diferente do que imaxinabas. O obxectivo é describir estruturas que a FPGA poida implementar de forma predecible: flip-flops, lóxica LUT, BRAM e bloques DSP, de modo que o comportamento e a temporización se alineen co teu intento.
Cando o mapeo é predecible, a depuración sente menos como discutir coas ferramentas e máis como refinar un deseño.
Un limiar cómodo para moitos principiantes é un único dominio de reloxo con lóxica sinxela e sincrónica. Utiliza bloques sempre acoplados para estados secuenciais e asignacións continuas (ou bloques combinacionais correctamente escritos) para camiños combinacionais. Crear lóxica “semellante ao reloxo” na estructura pode funcionar en casos específicos, pero tende a convidar a riscos de dominio de reloxo a menos que xa entiendas o control de reloxo, a ruteo e as implicacións de temporización.
O comportamento de reinicio é outro lugar onde pequenas eleccións poden crear resultados da placa sorprendentemente inconsistentes. Os reinicios asíncronos poden ser útiles, sen embargo, tamén poden producir perigos de desactivación ou sensibilidade a diferenzas de alimentación a nivel de placa. Moitos deseños de FPGA utilizan reinicios totalmente sincrónicos ou asunción asíncrona con liberación sincrónica porque estes enfoques axudan a reducir o comportamento incoherente de inicio durante as probas de subida.
A lóxica de FPGA naturalmente se apoia en tubaxes e estruturas paralelas. Un desacordo común entre principiantes é esperar unha execución paso a paso similar ao software, e logo sentirse confuso cando todo sucede a unha vez. Un enfoque máis útil é decidir que che importa para un bloque dado e logo deseñar explicitamente para ese resultado.
Un enfoque de deseño de liña única para rendemento e mapeo:
• Rendemento (elementos por reloxo)
• Latencia (ciclos desde a entrada á saída)
• Preferencia de mapeo de recursos (LUTs vs BRAM vs DSP)
Por exemplo, un multiplicador-acumulador pode inferir porciones de DSP de forma limpa, pero pequenos cambios no estilo de codificación poden inclinar a ferramenta cara unha aritmética baseada en LUT. Cando a utilización che sorprende, a miúdo vale a pena parar e facer unha pregunta lixeira incómoda: realmente describiches a estrutura de hardware que pretendías, ou describiches algo funcionalmente equivalente que custa máis recursos?
A simulación aceptará felizmente construcións que o hardware real non pode implementar da forma que poderías imaxinar. Manter o teu límite sintetizable claro reduce a falsa confianza e fai que os resultados da simulación sexan máis portátiles á placa.
Padróns comúns para manter agruparados nunha so linha como un recordatorio rápido:
• Evitalex delays (#) na lóxica sintetizábel
• Non dependas da inicialización a menos que confirmases o comportamento do dispositivo/ ferramenta
• Vixía os latches non intencionais de asignacións combinatorias incompletas
• Usa sincronizadores axeitados para cruces de dominio de reloj
Un hábito que tende a compensar é escribir bancos de proba autónomos pequenos que validen as supoñencias que emocionalmente estás tentado a ignorar: comportamento de reinicio, rebote de contadores, protocolos de apretón de mans e condicións extremas. Cando os proxectos medran, estas probas convertense menos en traballo adicional e máis na cousa que evita que dubides de todo.
Depura sistemáticamente con simulación e visibilidade na chip (ILA)
Mesmo a excelente simulación non promete un comportamento correcto da placa. O hardware real trae jitter de reloxo, retrasos de I/O, estados iniciais descoñecidos e entradas asíncronas que non se alinean cortésmente co teu borde de reloxo. Os depuradores máis rápidos non son normalmente aqueles que fan edicións aleatorias, son aqueles que reducen o problema cunha observación estruturada e poden explicar que evidencias mudaron a súa opinión.
Un forte banco de proba verifica o comportamento durante moitos ciclos e non evita escenarios incómodos. Se modelas estímulos realistas, a simulación convértese nun lugar onde construíres confianza, non só un lugar onde observas un sinal cambiar e esperas que signifique algo.
Estímulos realistas que tendan a expoñer lóxica fráxil:
• Rebote de botón
• Erros de enmarcado UART
• Presión de fondo en interfaces de transmisión
• Secuencias de reinicio con temporización incómoda
Tamén axuda a separar os erros en dous grupos para que non persigas o tipo equivocado de corrección:
• Erros funcionais: a lóxica do RTL é incorrecta
• Erros de integración: o RTL está ben, pero os reloxs/reinicio/asumptos de I/O non están correctos
A simulación é excelente para espremer erros funcionais; a proba da placa ten a forma de revelar erros de integración que non querías crer que eran posibles.
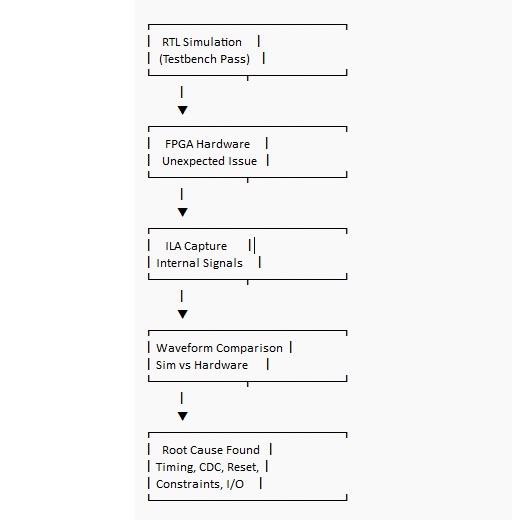
Cando o comportamento do hardware non coincide co teu banco de proba, o Analizador Lóxico Integrado (ILA) é moitas veces a forma máis directa de substituír a especulación cunha traza que podes estudar. Proba sinais que representan decisións e límites dentro do deseño, logo captura o momento en que as cousas diverxen e comparar con a onda de simulación esperada.
Sinais que tendan a ser sondas de alto valor:
• Codificación de estados de FSM
• apretóns de mans válidos/listos
• banderas de FIFO cheo/vacío
• saídas do xeral de reinicio
Un fluxo de traballo práctico consiste en comezar con menos sondas e unha maior ventana de captura. A medida que aprendes onde se atopa a falla, podes apretar o disparador e engadir detalle. A sobreinstrumentación pode reducir marxes de temporización e complicar as compilacións, así que adoita ser máis saudable tratar a inserción de ILA como un paso de medición centrado en vez de algo que mantés just in case.
Algúns dos fracasos máis educativos acontecen cando a simulación parece impecable e a placa é inestable. Esa discrepancia pode sentirse desmoralizadora, pero tamén é donde a intuición de FPGA se agudiza, porque a corrección xeralmente se atopa na temporización, restricións ou hixiene de sinais en vez de no algoritmo.
Causas comúns da diverxencia entre simulación/placa:
• Restricións de reloxo faltantes ou incorrectas
• Metastabilidade de entradas non sincronizadas
• Variación na temporización de liberación de reinicio a través do chip
• Problemas de CDC entre múltiples dominios de reloxo
• Diferenzas nas condicións iniciais
Unha perspectiva que tende a acelerar o aprendizaje é tratar a temporización e a observabilidade como propiedades que construídes deliberadamente no deseño. Cando os teus pequenos proxectos definen explicitamente os reloxs, restrinxen a I/O, sincronizan os cruces e expoñen sinais internos para a medición, pasas menos tempo agardando que funcione e máis tempo realizando melloras controladas e explicábeis. Esa mentalidade escálenase naturalmente desde un LED parpadeante a tubaxes máis grandes, interfaces e sistemas embebidos no mesmo dispositivo.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) e Intel (Altera) ambos envían familias de FPGA que parecen comparables sobre o papel, e é fácil sentirse seguro tras un escaneo rápido do folleto. O estado de ánimo tende a cambiar despois, cando as realidades de enxeñaría día a día comezan a decidir o ritmo: comportamento das ferramentas no teu dispositivo exacto e grao de velocidade, se a IP que asumiches que poderías usar é realmente licencible na túa organización, se un deseño de referencia realmente se alinea cos teus reloxs e reinicios e se o pechado de temporización permanece estable unha vez que o deseño se converte en nivel de produción.
Un proceso de selección mantense mellor cando tratas a FPGA como un sistema de entrega, dispositivo + ferramentas + IP + placas + documentación + manexabilidade a longo prazo, porque aí é onde os equipos gañan impulso (e durmen) ou acumulan ansiedade no horario en silencio.
| Característica |
Xilinx (AMD) |
Intel (Altera) |
| Posición no Mercado |
Históricamente o líder do mercado, coñecido pola ampla gama de produtos e por ser o primeiro en lanzarse ao mercado con novas tecnoloxías. |
Companheiro forte, particularmente poderoso en centros de datos e aplicacións de redes, aproveitando a destreza de fabricación de Intel. |
| Arquitectura Principal |
A lóxica baséase principalmente en táboas de procura de 6 entradas (LUTs), ofrecendo alta granularidade e flexibilidade. |
Utiliza Módulos de Lóxica Adaptativa (ALMs), que son máis complexos e pódense configurar como LUTs máis grandes, potencialmente mellorando a densidade de lóxica para certos deseños. |
| Conxunto de Software |
Vivado Design Suite e Vitis Unified Software Platform. A miúdo eloxiado pola súa interface amigable para desenvolvedores experimentados. |
Quartus Prime Design Suite. Algúns usuarios consideran que a súa GUI é máis intuitiva para principiantes e é coñecida por tempos de compilación máis rápidos en algúns escenarios. |
| Familias de Alto Rendemento |
Versal ACAPs (Adaptive Compute Acceleration Platforms) que combinan motores escalares, adaptables e intelixentes. |
FPGAs Agilex, coñecidos por alto rendemento e eficiencia enerxética, con algúns puntos de referencia que amosan unha vantaxe de rendemento por vatios. |
| Enfoque do Ecosistema |
Enfoque forte na integración do procesador e FPGA, como se pode ver na familia Zynq. Popular para o desenvolvemento de aplicacións. |
Ben adecuado para deseños de Sistema-en-Chip e aplicacións industriais, cun forte portfolio de IP para redes e RF. |
Definir Selección Usando Restricións Verificables, Non Expectativas de Marca
Comeza cos requisitos que podes probar cedo, non coas impresións de proxectos previos. O obxectivo é reducir "sorpresas na semana 10", que é onde a frustración e o traballo de reemprego tendemos a acumular.
Lista de verificación de restricións:
• Recursos lógicos: LUTs/ALMs, rexistros, dispoñibilidade de enrutamento e límite de utilización esperado
• Recursos DSP: conteo de bloques, modos de precisión, pre-sumadores, opcións de cascada/topoloxía e comportamento de mapeo para os teus núcleos matemáticos
• Memoria en chip: BRAM/URAM (ou equivalentes M20K), capacidade total, modos de porto, ancho de banda por reloxo e patróns de contención
• Entrada/Saída de alta velocidade: clase SERDES, conteo de carrís, taxa de liña máxima, opcións de reloxo de referencia e soporte de protocolo atado ao teu caso de uso
• Memoria externa: variantes DDR3/DDR4/LPDDR, madurez do controlador, comportamento de calibración e supostos de marxe SI a nivel de placa
• Latencia e determinismo: obxectivo de final a final, orzamento por etapa, tolerancia ao jitter e estratexia CDC (incluíndo como se cruzan os reinicios entre dominios)
• Envelope de potencia/térmica: estimacións de conmutación do peor caso, modos de potencia do transceptor, supostos de disipación térmica e rango ambiental
Proxectos reais de FPGA mostran a miúdo que encadearse no dispositivo non garante unha operación confiable a alta velocidade. Os deseños que parecen aceptables cunha utilización do 70-80% poden volverse inestables tras engadir lóxica de depuración, protección CDC, FIFOs, manexo de erro e marxe de tempo necesaria para unha operación práctica.
Se o teu equipo perdeu unha semana a causa da congestión de enrutamento, a atracción de aumentar un tamaño de dispositivo é fácil de entender. O intercambio de custos xeralmente non é lineal: unha peza un pouco máis grande pode comprar un tempo de espera máis tranquilo, menos iteracións de ferramentas e menos reconstrucións na noite.
Trata o Fluxo de Ferramentas Como un Requisito Que Non Podes Desexar
O fluxo de ferramentas tende a ser o separador oculto entre o plan que parece sólido e o plan que segue escorregando. A xente subestima a cantidade de ancho de banda emocional que se queima en iteracións lentas ou impredecibles, especialmente cando unha compilación leva horas e o modo de fallo é vago.
Lista de verificación da avaliación do fluxo de ferramentas:
• Velocidade de iteración: síntese + colocación/enrutamento + tempo de bitstream no teu hardware CI, non nunha máquina de demostración do vendedor
• Comportamento de peche temporal: tendencias de QoR, estabilidade entre sementes e sensibilidade a pequenos cambios de restrición
• Restricións e observabilidade: claridade SDC/XDC, precisión na modelaxe de reloxo, tratamento de camiños falsos/multiciclo e a que tan debuxados son as violacións
• Instrumentación de depuración: fluxo de inserción de analizador lixeiro, flexibilidade de sondeo, profundidade de disparo e cada canto debes recompilar para observar sinais
• Axuste do entorno: versións de SO soportadas, compilacións sen encabezado, fricción de licencias e como se axusta ao fluxo de traballo do teu equipo
• Amigabilidade CI/VCS: reproducibilidade, saídas deterministas (tanto como as ferramentas permiten), scriptabilidade e dor de actualización
Antes de comprometerte, realiza unha proba de peche temporal en algo representativo (non un xoguete). Inclúe os teus reloxs reais, polo menos unha interface de memoria externa e polo menos un bloque de I/O de alta velocidade. Seguimento:
• Tempo de compilación en tempo de parede por iteración
• Estabilidade do slack entre unhas poucas sementes
• Que tan rápido pode un enxeñeiro diagnosticar os primeiros tres problemas de tempo sen coñecemento tribal
Ese experimento tende a producir un tipo de claridade que as listas de verificación de características non producen. Tamén revela se o teu equipo se sentirá estable ou constantemente tenso durante a fase de integración.
Disponibilidade de IP e Licenzas: Onde as Programacións Comúnmente Se Apertan
Mesmo cando os recursos FPGA brutos se parecen, as programacións a miúdo dependen das realidades de IP. É aquí onde os equipos poden sentirse sorprendidos: o núcleo existe, pero o modelo de licenza, o esforzo de integración ou a calidade da documentación convérteno nun proceso lento.
Lista de verificación de IP e licenzas:
• Pilas de protocolos: PCIe, Ethernet MAC/PCS, JESD204, controladores DDR e calquera interface específica da que dependas
• Condicións da licenza: bloqueada por nodo fronte a flotante, complementos de características, implicacións do servidor de compilación/CI e calquera restrición de tempo de execución ou implementación
• Deseños de referencia: contaxes de vía, plan de sincronización, secuenciación de restablecemento, arquitectura DMA e se se adapta aos límites do teu sistema
• Horizonte de soporte: expectativas de mantemento a longo prazo, cadencia de actualizacións e como se clasifican os problemas
Un punto sutil que os equipos aprenden da maneira máis dura: o IP dispoñible non é o mesmo que o IP listo para usar. As demostracións de laboratorio poden ocultar o traballo de integración necesario para alcanzar os teus obxectivos de latencia, almacenamiento en búfer e sincronización. Planificar tempo para a validación e favorecer IP coas documentacións directas e exemplos probados a miúdo reduce o nivel de estrés máis adiante, mesmo se a avaliación inicial se sente máis lenta.
Ecosistema da placa, risco de arranque e a comodidade das plataformas probadas
A elección do FPGA está vinculada á realidade da placa. Durante o arranque, o tempo a miúdo desaparece na incerteza da plataforma en lugar de no RTL: unha restrición de sincronización perdida, unha dependencia de restablecemento que non era obvia ou un canal de transceptor que é marginal só a certas temperaturas.
Lista de verificación da placa e da plataforma
• Placas de avaliación e plataformas de referencia: dispoñibilidade, estabilidade da revisión e se o deseño é amplamente utilizado no campo
• Directrices de subministración de enerxía: obxectivos de PDN, enfoque de desacoplado, expectativas de secuenciación de vías e supostos de tolerancia apilados
• Referencias de distribución de alta velocidade: directrices de roteamento de transceptores, notas de conformidade e apilamentos probados
• Acceso de depuración: estabilidade de JTAG, modos de arranque/configuración, soporte de flash de configuración e visibilidade sobre vías/sincronización
• Capacidade de resposta ao soporte: canais de provedores, relación sinal-ruído da comunidade e tempo de resposta para problemas de ferramentas/IP
Usar unha plataforma amplamente adoptada con deseños de referencia probados pode facer que a activación do sistema sexa máis estructurada e predecible. Este enfoque axuda a que a solución de problemas pase dunha ampla incerteza a unha verificación medible paso a paso, mellorando a eficiencia no desenvolvemento.
Peche de tempo
O peche de tempo é onde as diferenzas entre provedores se volven tangibles, especialmente cando a utilización aumenta e múltiples dominios de sincronización interactúan. Neste momento, o progreso do deseño pode permanecer estable e predecible ou volverse difícil cando pequenos cambios crean grandes variacións de tempo.
• Escala de congestión: como aumenta a presión de roteamento a medida que a utilización sobe e onde comeza a aumentar
• Predicibilidade de Fmax: cada canto as restricións moderadas che achegan, en comparación coa necesidade de afinación manual intensa
• Calidade da informe: se os informes de tempo indican correccións accionables, non só longas listas de violacións
• Robustez: comportamento a través da variación de PVT e a través de sementes de implementación
A miúdo é máis seguro asumir que o esforzo de peche crece de maneira non lineal coa densidade. Pasando un certo limiar, un pequeno axuste de RTL pode cambiar o margen de tempo de saudable a frágil. O margen arquitectónico, a tubaxe, a planificación selectiva de chanzos e a elección dun dispositivo cunha marxe de erro, a miúdo superan a afinación heroica de restricións que a ninguén lle gusta manter.
Comparar a peza exacta
As especificacións cambiantes entre xeracións e dentro dunha única familia. Duas pezas con nomes semellantes poden comportarse de xeito diferente suficiente para interromper un plan, especialmente unha vez que a embalaxe, a categoría de velocidade e a madurez da ferramenta entran en xogo.
• Categoría de velocidade: Fmax alcanzable, comportamento do margen de transceptor e diferenzas no modelo de tempo
• Embalaxe: contaxes de I/O, colocación de bancos, impacto de SI, comportamento térmico e restricións de montaxe
• Límites de características SKU: bloques desactivados, capacidade de transceptor reducida, proporcións de memoria ou limitacións de protocolo en certas variantes
• Madurez da ferramenta: nivel de soporte do dispositivo, cadencia de lanzamento e se o teu equipo pode estandarizar en versións de ferramenta estables
Método de comparación práctica:
• Modelos de tempo do provedor mapeados aos teus reloxs e interfaces reais
• Estimación de potencia utilizando taxas de alternancia realistas, ciclos de traballo e configuracións de transceptor
• Restricións de pinout/banco alineadas coas túas esixencias de placa e mapa de conectores
• Versións de ferramenta coas que a túa organización pode convivir durante a vida do produto (incluíndo CI)
Un marco de decisión que tende a conservarse cando as cousas se fan estresantes
Cando a presión do horario aumenta, un marco baseado en medidas axuda a evitar pivotes impulsados polo arrepentimento. Tamén axuda ao equipo a sentirse máis asentado, porque as decisións teñen unha trazabilidade documental vinculada a resultados observados en vez de optimismo.
Orde de selección equilibrada:
1) Bloquear requisitos medibles: recursos, I/O, memoria, latencia e orzamento de potencia/térmica.
2) Prototipar o subsistema máis difícil de cada candidato: comportamento de temporización + fluxo de depuración + bucle de construción/CI.
3) Avaliar a madurez da propiedade intelectual e a licenza en función do seu plan de integración, non dos resumos de marketing.
4) Escoller a opción con marxe e o bucle de iteración máis predecible, en lugar da que apenas cumpre cos mínimos.
O principal ensino é que o mellor FPGA rara vez é o que ten os números de titular máis brillantes. Os equipos normalmente avanzan máis rápido e con menos dúbidas cando a plataforma apoia a converxencia constante, construcións repetibles e solucións mantibles ao longo da vida do produto.
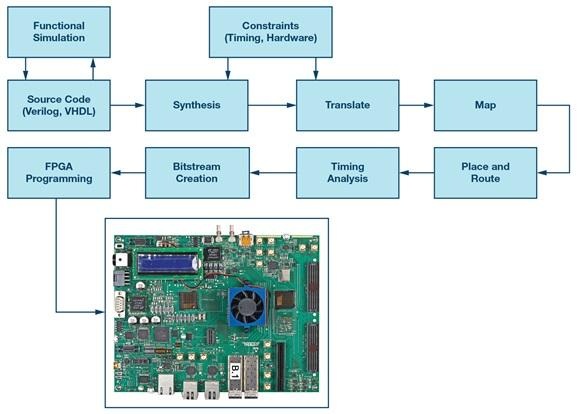
O Conxunto de Ferramentas Principal

O Papel de Vivado no Fluxo de Traballo do FPGA
Vivado tendencialmente converteuse no núcleo operativo dun proxecto FPGA de Xilinx, non porque sexa glamouroso, senón porque é onde cada suposición finalmente se pon a proba contra a realidade das ferramentas. Inxecta HDL e restricións, produce unha lista de redes, execútase a colocación e o enrutamento equilibrando as regras de temporización e deseño físico, e despois xera un bitstream que programa o dispositivo.
Unha forma práctica de entender Vivado é velo como dous sistemas conectados: un sistema de conversión RTL-a-lista de redes e un optimizador de implementación física. Isto explica por que o RTL lóxicamente correcto pode producir resultados inestables ou inconsistentes cando as restricións son incompletas, as definicións de reloxo son inexactas ou a estrutura do deseño crea dificultades de enrutamento e temporización.
A maioría dos proxectos seguen un fluxo coñecido, incluso cando os detalles difiren segundo a familia de dispositivos e o estilo de fluxo.
• Síntese: traduce RTL a unha representación a nivel de compoñente e infire estruturas específicas do dispositivo.
• Implementación: realiza colocación, enrutamento e optimización impulsada por temporización baixo restricións físicas.
• Xeración de bitstream: emite a imaxe de configuración e verifica o resultado implementado fronte ás restricións e regras da ferramenta.
Un horario tende a volverse tenso non cando se produce un bitstream unha vez, senón cando o equipo necesita que o bitstream se comporte como unha saída fiable: resultados similares en reconstruccións, márxenes de temporización que sobreviven na grao de velocidade de destino, e estabilidade cando se fan pequenas edicións en RTL para correccións funcionais. É aí onde o que se construíu onte deixa de ser reconfortante.
Os equipos que avanzan máis rápido co tempo normalmente deixan de tratar os informes como traballo administrativo e comezan a tratalos como probas de enxeñería. Cando os artefactos de construción se recollen de forma consistente, as discusións sobre o deseño volven ser menos emocionais e máis concretas, o que é un alivio cando os prazos están próximos.
• Informes de síntese/implementación: utilización, primitivos inferidos, advertencias e resumos estruturais.
• Saídas de temporización: WNS/TNS, puntos finais fallidos, camiños detallados e resumos da interacción do reloxo.
• Restricións XDC: reloxs, regras de I/O, excepcións e asignacións de pines físicos.
• Puntos de control implementados (DCP): instantáneas reproducibles que apoian iteracións rápidas e experimentos controlados.
Un patrón que aparece no traballo real é que un conxunto de informes ordenados e internamente consistentes predí a progresión máis fluída que un único banner verde "PASS". O banner pode ocultar fragilidade; os informes normalmente non.
Instalación e Configuración do Entorno
Unha configuración que simplemente lanza a GUI é fácil de celebrar e fácil de arrepentir despois. As configuracións nas que os equipos confían son aburridas dunha boa maneira: comportan-se igual baixo automatización, son consistentes entre máquinas e non sorprenden despois dun actualización da ferramenta.
Elixe a edición de Vivado ML que se adapte aos teus obxectivos de dispositivo, despois habilita só as familias de dispositivos que realmente planeas construír. Isto reduce o uso de disco e o tempo de indexación, e tamén diminúe as posibilidades de cometer erros de configuración cruzada entre familias que poden consumir unha tarde.
En equipos de desenvolvemento multi-táboa, manter unha lista definida de dispositivos soportados para cada proxecto axuda a manter o desenvolvemento máis controlado e consistente que confiar nos dispositivos ou partes que suceden estar instalados.
As saídas de Vivado poden cambiar entre versións porque os algoritmos de colocación, enrutamento e temporización evolucionan e as correccións de erros se realizan (ou son substituídas por diferentes erros). Moitos equipos logran construcións máis calmadas asignando unha versión da ferramenta por rama de lanzamento e actualizando en pasos planificados en lugar de derivar continuamente.
Ao probar unha versión máis nova, os equipos comparan frecuentemente os sinais prácticos da saúde da ferramenta antes de adoptala como nova there: marxes de temporización, cambios de utilización, deltas de advertencia e calquera novo mensaxe de cobertura de restricións. O tempo spent en facer esa comparación é normalmente máis fácil que discutir tarde no ciclo se a temporización de súpeto empeorou sen razón.
Para as compilacións de liña de comandamento, sistemas CI e servidores de compila compartidos, o entorno de desenvolvemento debe comportarse de maneira consistente en todos os sistemas en lugar de depender das configuracións de máquina individuais.
• Scripts de configuración: fonte as configuracións da ferramenta correcta para que as rutas, bibliotecas e dependencias de execución se resolvan de forma consistente.
• Fluores impulsados por Tcl: preferir compilacións scriptadas para execucións repetibles, informes uniformes e integración CI.
• Disciplina da interface de compilación: manter entradas e saídas estables para que os cambios sexan intencionais e revisables.
Un fluxo de traballo de desenvolvemento común consiste en completar primeiro unha compilación GUI estable para verificar o deseño, e logo pasar a un fluxo baseado en Tcl para que o proceso de compilación xa non dependa das configuracións de GUI, datos en caché ou diferenzas entre máquinas de desenvolvemento.
Os Informes que Quere Leer como Diagnósticos
A maioría dos momentos de falla do deseño non son misteriosos durante moito tempo se os informes se leen como unha historia do que a ferramenta creu. As advertencias, a cobertura de restricións e os camiños de temporización tendan a documentar o modo de falla á vista, aínda que non sempre na orde máis amigable.
Os equipos melloran máis rápido cando tratan as saídas de Vivado como un bucle de retroalimentación diaria en lugar de algo que se abre só cando a compilación se rompe.
Estes informes son frecuentemente o primeiro lugar onde a deriva de intención se fai visible, e iso pode ser paradoxicamente tranquilizador: polo menos o problema é concreto.
• Utilización de recursos: LUT, FF, BRAM, DSP, URAM versus límites e marxe do dispositivo.
• Comprobacións de inferencia: estilos de RAM inesperados, falta de inferencia de DSP, mapeo primitivo sorprendente.
• Bandeiras vermellas estruturais: redes de alta salida, muxión ampla, longas cadeas combinatorias.
• Advertencias: inferencia de latch, manexo incompleto da sensibilidade, lóxica non conectada ou recortada.
A inferencia de latch e os camiños combinatorios longos non intencionados aparecen frecuentemente na práctica. A ferramenta implementará eles sen queixas, e iso pode sentirse enganoso cando a temporización despois se nega a cooperar de maneiras que parecen aleatorias ata que se leven a cabo os informes de camiños.
O peche de temporización convértese en menos estresante cando o equipo sabe o que a ferramenta está optimizando e por que está elixindo certos compromisos.
• Sinais de holgura: WNS como a peor violación única; TNS como a extensión total das violacións.
• Desglose de camiños: onde se acumula o retraso (profundidade lóxica, enrutamento, reloxo ou suposicións de restricións).
• Modelado de reloxo: se os camiños son analizados como se pretendía, ignorados ou agrupados de maneira incorrecta.
Unha lección matizada que os equipos experimentados internalizan é que o dolor de temporización é, a miúdo, un problema de modelado de restricións primeiro e un problema RTL segundo. Cando o modelo de reloxo é incorrecto, pode pasar días optimizando os wrong endpoints e aínda así sentir que a ferramenta non está escoitando.
As brechas de restrición son un delincuente repetido, en parte porque non sempre parecen dramáticas ata que o proxecto está moi avanzado.
• Brechas na definición do reloxo: reloxs primarios faltantes ou incorrectos.
• Brechas de reloxo xeradas: reloxs divididos/multiplicados/encaminhados non declarados, forzando a ferramenta a adiviñar.
• Brechas na definición de I/O: restricións de I/O faltantes que conducen a suposicións optimistas e posteriormente sorpresas a nivel de placa.
• Mal uso de excepcións: excepcións faltantes ou excepcións que son demasiado amplas para ser fiables.
Un hábito pragmático é tratar o XDC como unha especificación viva en lugar de como un arquivo de parche. Cando se introducen excepcións, os equipos que dormen mellor tendes a mantelas estreitas, explicadas e vinculadas a unha relación de temporización real en lugar de usalas para calmar violacións que merecen escrutinio.
Estratexias de restricións XDC
O arquivo XDC é onde a intención de deseño se ve forzada a converterse en explícita. Cando está lixeiramente mal, o comportamento de temporización resultante pode parecer caótico a pesar de que a ferramenta é perfectamente determinista.
Define reloxs de forma explícita, e logo verifica que a ferramenta os propagou do xeito que esperabas. Os problemas de modelado de reloxo son a miúdo máis fáciles de corregir que problemas de temporización arquitectónicos máis profundos, o que os fai máis simples de resolver durante a análise e depuración de temporización.
• Reloxs primarios: definidos a partir de pines ou saídas de MMCM/PLL.
• Reloxs xerados: definidos para dominios divididos, multiplicados ou encamiñados.
• Relacións asíncronas: declaradas a través de grupos de reloxo ou relacións explícitas.
En placas reais, un reloxo xerado perdido pode producir unha imaxe de temporización enganosa que queima días, especialmente cando a ferramenta optimiza cara a endpoints que nunca se pretendía que se analizaran xuntos.
As restricións de I/O modelan as suposicións eléctricas e de temporización que utiliza a ferramenta, e iso pode determinar en silencio se o éxito do laboratorio se converte en "éxito do sistema".
• Normas eléctricas: normas de I/O e voltaxes alineados co deseño da placa.
• Disciplina de pinos: bloquear as localizacións dos pinos unha vez que a asignación se estabilice para evitar cambios constantes.
• Temporización da interface: retrasos de entrada/salida que reflexan o dispositivo externo, non as predicións por defecto da ferramenta.
Un desengaño familiar na fase tardía é: cumpriu co tempo na construción, pero a interface falla baixo tráfico real. Ese resultado a miúdo remonta a suposicións de I/O por defecto que nunca foron actualizadas para coincidir co orzamento de temporización da placa e do dispositivo externo.
As excepcións poden clariar a intención, e tamén pueden crear unha ilusión frágil de progreso se sobreviven á súa xustificación orixinal.
• Camíns falsos: usados só cando o camiño non é parte da temporización funcional.
• Camíns multicículo: usados só cando a relación de captura realmente se estende a múltiples ciclos e está documentada.
• Hixiene das excepcións: mantén o conxunto pequeno, revísao despois de cambios maiores no RTL/pipeline, e retira entradas obsoletas.
Algúns dos erros de temporización máis caros provéñen de excepcións que foron precisas unha vez, logo volven a ser silenciosamente imprecisas tras un cambio no pipeline. A ferramenta cumprirá sen queixas, que é precisamente o que fai que este modo de falla sexa tan desagradable.
Patrones de falla típicos e como resolvelos eficientemente
Certos problemas repítense en proxectos, independentemente de se a aplicación é redes, visión, control ou aceleración. Reconocer o patrón cedo tende a reducir a carga emocional da depuración, porque o equipo pode pasar de por que está a suceder isto a que libro de xogos se aplica.
Esta situación a miúdo parece que a ferramenta é teimuda, pero as causas raíz adoitan ser rastrexables.
• Profundidade combinacional: camíns longos causados por falta ou insuficiente tubaxe.
• Presión de fanout: redes de control de alto fanout que se benefician da replicación, almacenamento ou reestruturación.
• Modelado de restricións: definicións de reloxo ou relacións que mal caracterizan o que debería ser analizado.
Una secuencia que tende a funcionar ben é: validar o modelo de temporización (reloxos e relacións), concentrarse primeiro nos puntos finais que fallan máis, logo ampliar a cambios arquitectónicos só se as probas do camiño o apoian.
Esta é unha das experiencias máis desmoralizadoras no traballo con FPGA, principalmente porque parece que a realidade é injusta. Normalmente, só é que a simulación non stressou os mesmos modos de falla.
• Comportamento de CDC/reset: secuenciación de reinicio e cruces de dominio de reloxo que a simulación raramente exerce de maneira realista.
• Suposicións de I/O: I/O descontrolado ou mal controlado que produce interfaces reais marginais.
• Comportamento de inicialización: confianza en valores iniciais que non se mapearán limpa e precisamente ao comportamento de encendido do dispositivo.
Os equipos que se tornan máis estables introducen a Estratexia de CDC e reinicio na discusión de deseño desde o principio, tratándoas como parte da arquitectura de deseño en lugar de como unha fase de limpeza após que a "lógica real" estea feita.
Este problema é común porque o lugar e a ruta responden dunha maneira aguda aos cambios na estrutura da netlist, incluso cando o cambio funcional parece menor.
• Sensibilidade da netlist: pequenos refactorizados poden alterar as decisións de empaquetado, colocación e congestión de rutas.
• Deriva de restricións: pequenos cambios en XDC (ou cobertura faltante) poden amplificar a variación de temporización.
• Hábitos de mitigación: implementación incremental, preservación selectiva da jerarquía e restricións estables.
Cando os equipos adoptan estes hábitos de mitigación, a iteración tende a parecer máis predecible, o que reduce a tentación de conxelar o deseño prematuramente por medo a romper a temporización de novo.
Consideracións sobre licenzas
A licenza tende a converterse nunha conversación cando un proxecto se atopa cos límites de cobertura do dispositivo ou cando se precisan características avanzadas para un fluxo de traballo particular.
• Estándar: adoita alinear con placas de aprendizaxe de entrada e de gama media e fluxos de base.
• Empresa: adoita alinear cun maior soporte de dispositivos e capacidades avanzadas.
Para os equipos, as licenzas flotantes respaldadas por un servidor de licenzas son a miúdo máis fáciles de escalar que as licenzas bloqueadas por nodo, especialmente cando as construcións se executan en máquinas compartidas, servidors de construción dedicados ou corredores de CI. Moitos equipos prefiren alinear a licenza co mapa de dispositivos antes que despois, porque as sorpresas de licenzas teñen a costum de aparecer cando cambiar de dispositivos xa é caro e políticamente difícil.
Un bucle de enxeñaría consistente tende a predecir un progreso máis estable que calquera optimización intelixente única: manter as limitacións alineadas coa realidade, ler informes rutineiramente (incluso cando preferirías non hacerlo), solucionar causas raíz en lugar de calar síntomas, e manter as compilacións reproducibles. Cando ese bucle está establecido, Vivado sente menos como unha caixa negra e máis como un paneis de instrumentos, e o peche de tempo pasa de ser unha tensión no último minuto a algo que o equipo pode xestionar deliberadamente.
Portfolio e ecosistema de Xilinx

Escoller entre os dispositivos de Xilinx tende a ir máis suave cando o punto de partida é a integración circundante (procesadores, interfaces de memoria, ruta de arranque e dependencias a nivel de placa), non só unha comparativa dos totais de LUT en bruto. Esa enmarcación xeralmente empátrase co que os horarios reais e os riscos reais amosan.
Un FPGA discreto tende a encaixar cando o equipo quere plena propiedade da arquitectura da placa e a carga de traballo inclínase cara a un comportamento de hardware determinista cun área de superficie de software mínima. Un SoC de clase Zynq tende a encaixar cando o deseño se beneficia dun CPU que está preto da lóxica de aceleración para que o control e a ruta de datos poidan evolucionar xuntos sen converter a placa nunha negociación de múltiples chips. Un módulo estilo Kria SOM tende a encaixar cando o plan é moverse rápido e limitar a incerteza do arranque da placa tratando computación, memoria e almacenamento de arranque como un bloque de construción prequalificado.
O FPGA discreto tende a encaixar para:
• control máximo do deseño da placa
• tubaxes deterministas cunha dependencia limitada do software
O SoC Zynq tende a encaixar para:
• acoplamento CPU+acelerador estreito
• computación/unificación do control nun único dispositivo
• evolución iterativa de HW/SW
O Kria SOM tende a encaixar para:
• menor tempo ata o produto
• exposición a nivel de placa reducida utilizando un subsistema de computación validado
Os FPGAs simples adoitan funcionar ben cando o problema está impulsado por presión de peche de tempo, necesidades inusuales de I/O, ou tubaxes de transmisión que funcionan mellor como hardware de función fixa. A latencia predecible e as rutas de datos estruturadas a miúdo melloran o control, a verificación e a depuración, especialmente cando a arquitectura se mantén ben organizada.
Os dispositivos autónomos aparecen frecuentemente en:
• interface de sensores
• control de motores
• procesamento de paquetes a taxa moderada
• pontificación de protocolos
No campo, unha fonte recorrente de frustración non é o RTL en si senón as obrigacións circundantes da placa que chegan en silencio e logo dominan a ruta crítica. As liñas de fournimentación, a configuración e a estratexia de arranque, a xeración de reloxo, a distribución de memoria externa (cando está presente) e o acceso de depuración poden converterse nas limitacións que moldean todo o produto. Unha regra práctica é que canto máis sinxela sexa a historia da memoria externa e menos transceptores de alta velocidade estean implicados, máis satisfactoria se converte a experiencia do FPGA autónomo. Apenas as correntes DDR externas e os fluxos de arranque de varios pasos se fan ineludibles, a atracción da integración dun SoC ou un módulo comeza a sentirse menos como unha característica e máis como un alivio.
As familias optimizadas para o custo xeralmente buscan unha mestura medida de LUTs, BRAM e DSP baixo orzamentos de potencia restrinxidos. Aparecen moito en produtos onde o equipo de enxeñería quere capacidades respectables sen pagar a taxa da placa e térmica que vén con interfaces extremas.
As zonas de aterraxe comúns inclúen:
• control embebido
• agregación de I/O de gama media
• procesamento de sinais a velocidade moderada
O lado positivo non é só o prezo por unidade, os equipos adoitan apreciar que estas pezas facilitan quedarse dentro dos límites térmicos sen ter que recorrer a sistemas de refrixeración agresivos, e poden evitar que a PCB se converta nun proxecto de distribución de alta velocidade. Ao mesmo tempo, as compilacións no campo ensinan regularmente unha lección algo incómoda: un dispositivo de menor custo pode acender un gasto total máis alto se obriga a compromisos de deseño na etapa final. Cando o margen de tempo é escaso, pequenos axustes, un cambio de estándar de I/O, un pequeno retoque do encamiñamento do reloxo, un cambio de plano de planta, poden causar ondas no caos de verificación e a ansiedade no calendario. Para estes dispositivos, os equipos xeralmente aforran tempo asentando a planificación do dominio de reloxo, a estratexia CDC e o comportamento de reinicio cedo, en lugar de esperar que as micro-optimizacións tardías salven o plan.
SoCs Zynq
Os dispositivos Zynq combinan procesamento ARM con lóxica programable, o que permite que o deseño se divida en software do plano de control e aceleración do plano de datos dunha forma que parece natural para moitos equipos de produto. Esto non só mellora a conveniencia, senón que reconfigura o fluxo de traballo. Os equipos poden comezar cunha referencia centrada no software para a confianza funcional, e logo migrar rutas quentes a hardware a medida que os requisitos de rendemento e latencia se volven menos negociables.
En implementacións que envellecen ben, o CPU rara vez "substitúe" o hardware, tende a estabilizar o produto. O procesador acaba manexando a configuración, a telemetría, as actualizacións de campo, a política de seguridade e a conectividade de borda, mentres que o tecido xestiona tubaxes determinísticas. Esa separación pode ser emocionalmente tranquilizadora para os mantedores: o software absorbe cambios, o hardware mantén a estabilidade e as versións senten menos como unha aposta.
O CPU normalmente leva:
• configuración
• telemetría
• actualizacións
• política de seguridade
• conectividade de borda
O tecido normalmente leva:
• tubaxes de transmisión determinísticas
• aceleradores estables
• camiños de datos sensibles á latencia
A medida que a densidade de cálculo aumenta e as interfaces se volven máis esixentes, as pezas ao estilo Zynq UltraScale+ reducen a complexidade da placa e do sistema ao achegar núcleos de CPU, controladores DDR e interconexión de alta capacidade máis cerca do tecido. Isto se volve atractivo en deseños que necesitan tanto determinismo en tempo real como un ambiente de software capaz, especialmente cando a carga de traballo é unha mistura en vez de un só núcleo limpo.
Exemplos de casos de uso frecuentes inclúen:
• analíticas de borda
• fusión de múltiples sensores
• tubaxes mesturadas de tempo real máis IA
Un detalle que os equipos experimentados aprenden a respectar é que "máis tecido" non se traduce automáticamente en "máis rendemento entregado". Os proxectos a miúdo topan con teitos de ancho de banda de memoria antes de quedarse sen DSPs ou LUTs. Os deseños que deciden sobre a topología DMA, a estratexia de almacenamento en búfer e as expectativas de coherencia de caché desde o principio tende a alcanzar un rendemento estable con menos alteración que os deseños que pospoñen as decisións de movemento de datos ata unha integración tardía.
A partición rara vez se trata de se algo podería ser acelerado, senón máis de se a aceleración compensa dado o esforzo de verificación, a complexidade do controlador e do tempo de execución, e con que frecuencia se espera que a lógica cambie. Os equipos a miúdo senten unha loita aquí: empurrar demasiado cara ao hardware pode ralentizar a iteración, mentres que deixar demasiado sobre o CPU pode deixar os obxectivos de rendemento perpetuamente case alcanzados.
Cargas de traballo que frecuentemente permanecen no CPU máis tempo do esperado inclúen:
• lóxica que cambia rapidamente
• comportamento complexo e intenso en análise
• características con ciclos de iteración rápida
Cargas de traballo que a miúdo recompensan a aceleración temperá do tecido inclúen:
• algoritmos estables
• núcleos densos en cálculos
• camiños de datos amigables para a transmisión
Un patrón pragmático é comezar cunha pequena porción de extremo a extremo, a miúdo un simple bucle DMA de retroalimentación máis un acelerador mínimo, antes de construir conxuntos de características completos. Ese prototipo limitado tende a aflorar os problemas de integración que doutro xeito chegarían tarde e a un alto custo: comportamento de interrupción, alineación de búfer, custo de mantemento de caché, e teitos de rendemento que só aparecen baixo carga sostida.
Kria SOMs e plataformas estilo módulo
Os Kria SOMs empaquetan cálculo, memoria e almacenamento de arranque nun subsistema listo, desviando o esforzo do arranque da placa cara á enxeñería de aplicación. A miúdo, os equipos prefiren este enfoque porque contén incertidume: a integridade do sinal, o enrutamento DDR, a secuenciación de potencia e a fiabilidade do arranque xa están validadas, o que pode facer que as primeiras demostracións se sintan menos fráxiles e a planificación se sinta menos especulativa.
O enfoque tende a funcionar especialmente ben cando a diferenciación vive en algoritmos, topología de I/O e fiabilidade de implementación, en vez de nunha placa de cálculo personalizada. Tamén pode reducir a fricción entre equipos: o traballo de hardware, firmware e aplicación pode avanzar en paralelo con menos momentos de "bloqueado por arranque".
A integración do SOM validada normalmente cobre:
• integridade do sinal
• enrutamento DDR
• secuenciación de potencia
• fiabilidade do arranque
Os equipos poden reenfocar o esforzo en:
• diferenciación da placa portadora
• integración de firmware
• comportamento da aplicación
• endurecemento da implementación
Un SOM a miúdo ten un custo por unidade máis alto que unha placa totalmente personalizada, con todo, o custo total do programa pode caer cando os prazos son axustados ou o risco de rendemento de fabricación é incómodo. O beneficio menos obvio é a previsibilidade do ciclo de vida: cun módulo, o cálculo a miúdo pode ser tratado como un elemento intercambiable entre variedades de produtos, reducindo a rotación de redeseños cando os requisitos cambian a medio proceso.
O paso máis tranquilizador é validar cedo que a capacidade térmica, a exposición I/O e o ancho de banda da memoria do SOM realmente coinciden coas cargas de traballo pretendidas, en vez de confiar na lectura dunha ficha técnica. Se a aplicación acaba encorsetada polo ancho de banda, a afinación na fase tardía tende a sentirse como empuxar unha porta pechada, a descoordinación entre a demanda de acelerador e o subsistema de memòria do módulo simplemente domina.
As comprobacións de encaixe temperás normalmente inclúen:
• envoltura térmica
• I/O exposta
• ancho de banda de memoria sostido en comparación coa demanda de carga de traballo
Despliegue de IA no ecosistema
Vitis AI axuda a converter modelos adestrados en deseños de inferencia baseados en FPGA utilizando formatos de menor precisión, frecuentemente INT8, e compilándoos para arquitecturas de estilo DPU. Isto confirma rapidamente se un modelo pode operar na plataforma FPGA. A rendibilidade real, con todo, depende moito do deseño do sistema circundante, especialmente do movemento de datos e o manexo da memoria.
O rendemento final, en xeral, vén determinado por como de forma consistente o sistema pode alimentar o DPU. A estratexia de agrupamento, a disposición dos tensores, a programación de DMA, o dobre buffer e a colocación da memoria xeralmente deciden os FPS entregados máis que a cabeceira computacional. Os equipos que tratan o DPU como un consumidor de transmisión constante, con buffers cuidadosamente organizados, tendan a evitar a decepción común de TOPS teóricos impresionantes pero resultados a nivel de sistema decepcionantes.
Os controis para dar forma ao rendemento normalmente inclúen:
• estratexia de agrupamento
• disposición dos tensores
• programación de DMA
• dobre buffer
• colocación da memoria
Nos despregamentos, as eleccións minoritarias de implementación acumúlanse dunha maneira que pode ser difícil de prever a partir de microbenchmarks de laboratorio. Os buffers desalineados poden reducir silenciosamente o ancho de banda efectivo. O mantemento excesivo da caché pode consumir tempo de CPU e crear xitter. Os pipes de copiado intensivo poden borrar gran parte do beneficio obtido da cuantificación. Un enfoque fundamentado é medir o ancho de banda e a latencia en cada límite e logo concentrar esforzos no límite que actualmente está máis apertado.
Os límites de medición útil inclúen:
• sensor a DDR
• DDR a acelerador
• acelerador a post-procesamento
Un modelo mental útil é ver a tubaxe de IA como unha rede de fluxo constrinxida. Con esa estrutura, a selección do dispositivo volve ser menos sobre perseguir o número de cálculo máis grande e máis sobre escoller a opción que alivia o botleneck dominante e mantén o comportamento da tubaxe predecible.
Ecosistema e habilitación
O ecosistema Xilinx se extende máis alá do silicio á habilitación circundante que mantén os equipos en movemento: cadeas de ferramentas, IP, deseños de referencia, placas de socios e recursos de adestramento. Nos ambientes académicos, o Programa Universitario é a menudo apreciado porque reduce o dolor de configuración recorrente, o acceso ás ferramentas, a dispoñibilidade de placas e a estructura de laboratorio, de xeito que o progreso inicial é menos probable que se detenga por problemas de ambiente en lugar de aprendendo a enxeñaría real.
Os compoñentes do ecosistema inclúen:
• cadeas de ferramentas (Vivado, Vitis)
• catálogos de IP
• deseños de referencia
• placas de socios
• programas de adestramento
• recursos do Programa Universitario
Unha vez que a fricción de incorporación se reduce, os aprendices poden investir a súa enerxía nos hábitos que se traducen directamente en traballo profesional: rutinas de peche de tempos, disciplina de tubos, estratexia de verificación e xulgamento de co-deseño de hardware/software. Esas habilidades tendan a mostrar o seu valor durante a integración, cando os resultados se moldean máis pola velocidade de iteración e a cohesión do sistema que por un benchmark de núcleo illado.
As habilidades transferibles inclúen:
• hábitos de peche de tempos
• disciplina de tubos
• estratexia de verificación
• co-deseño de hardware/software
Un principio de selección que permanece consistente a través da liña
Un enfoque de selección fiable comeza desde as restricións do sistema en lugar de tiers de marketing. Os equipos, en xeral, obtén decisións máis claras cando anotan os obxectivos de funcionamento e as realidades do proxecto desde o principio, logo escollen o nivel de integración, FPGA, Zynq SoC ou SOM, que reduce as maiores fontes de incerteza para o seu programa específico. Isto tende a producir eleccións que se senten mellor meses despois, cando a integración e a velocidade de iteración importan máis que unha comparación de pezas sobre papel.
As restricións que deben definirse cedo inclúen:
• obxectivos de latencia
• necesidades de ancho de banda sustentadas
• requisitos de interface
• límites térmicos
• cadencia de actualización
• orzamento de verificación
En moitos programas, a opción que mantén o movemento de datos simples e o ciclo de desenvolvemento apertado acaba sendo a que mellor perdoa a idade, mesmo se o seu prezo por unidade non sexa o máis atractivo a primeira vista.
Conclusión
Aprender o deseño de FPGA de Xilinx volve ser máis fácil cando cada proxecto segue un proceso estable e repetible. Os resultados sólidos dependen dun HDL limpo, restricións correctas, comprobacións de tempos coidadosas, simulación e validación en hardware real. Ao comezar con deseños sinxelos e construír bos hábitos de depuración, os principiantes poden desenvolver habilidades fiables de FPGA para sistemas dixitais máis avanzados.
Preguntas Frecuentes [FAQ]
1. Por que os principiantes de FPGA a miúdo teñen dificultades mesmo cando o seu código HDL parece loxicamente correcto na simulación?
Moitos problemas temperáns de FPGA non son causados polo RTL en si, senón polo desaxuste entre as suposicións de simulación e o comportamento físico do hardware. A simulación adoita ocultar problemas relacionados cos constrains de reloxo, o tempo de reinicio, os estándares de I/O, a metastabilidade e o peche de tempo. Un deseño pode simularse perfectamente mentres que falla en hardware porque as ferramentas de FPGA interpretan os reloxs de forma diferente, os constrains son incompletos ou as entradas asincrónicas son manexadas incorrectamente.
2. Por que se consideran os constrains de tempo como unha parte central do deseño de FPGA en vez de un paso final de optimización?
Os constrains de tempo definen como as ferramentas de FPGA interpretan os reloxs, as relacións de tempo de I/O, os reloxs xerados e os dominios asincrónicos. Sen constrains precisos, Vivado pode optimizar o deseño utilizando supoñeduras incorrectas, levando a informes de tempo enganosos e a un comportamento inestable do hardware. Moitas fallas de FPGA ocorren mesmo cando a lóxica en si é correcta porque os reloxs non foron declarados correctamente, o tempo de I/O foi ignorado ou as excepcións foron aplicadas de forma demasiado ampla. Na práctica, os constrains actúan como unha descrición formal da intención do deseño, permitindo que as ferramentas constrúan hardware que se ajuste ao comportamento eléctrico real.
3. Por que a depuración de FPGA a miúdo require tanto simulación como ferramentas on-chip como ILA?
A simulación é altamente efectiva para detectar erros funcionais, pero non pode reproducir completamente os efectos reais do hardware como xitter, entradas asincrónicas, atrasos a nivel de placa, metastabilidade e variación ao encender. As ferramentas de depuración on-chip como o Analizador Lógico Integrado (ILA) proporcionan visibilidade nos sinais internos de FPGA mentres o sistema opera en condicións reais. Isto permite capturar transiciones de estado reais, comportamento de FIFO, saúdos e relacións de tempo directamente dentro do dispositivo. Combinar a simulación cunha depuración ILA crea unha comprensión máis completa de por que o hardware diverxe do comportamento esperado.
4. Por que os engenñeiros de FPGA experimentados prefiren fluxos de traballo disciplinados e repetibles en vez de configurar constantemente os proxectos?
Os fluxos de traballo repetibles reducen a incerteza e facilitan a illación de fallos. Usar a mesma placa de desenvolvemento, estrutura de reloxo, estratexia de reinicio e plantilla de proxecto permite aos enxeñeiros centrarse na lóxica que se está desenvolvendo en vez de depurar repetidamente o propio entorno. Os proxectos de FPGA implican moitas variables interactivas, incluíndo constrains, reloxeo, comportamento de síntese e configuración a nivel de placa. Cando demasiadas variables cambian simultaneamente, a depuración convértese en impredecible e emocionalmente agotadora. Os fluxos de traballo estables melloran a confianza porque os cambios poden rastrearse a decisións de deseño específicas en lugar de a diferencias ambientais descoñecidas.
5. Por que o deseño de hardware de FPGA é fundamentalmente diferente da programación de software tradicional?
O software executa instrucións de forma secuencial, mentres que o hardware de FPGA opera a través de estruturas lógicas concorrentes que funcionan simultáneamente. O HDL describe o comportamento físico do hardware en lugar do fluxo de execución procedural. Os principiantes a miúdo esperan un comportamento similar ao software, e logo confúndense cando múltiples bloques de hardware reaccionan ao mesmo tempo no mesmo borde de reloxo en paralelo. O deseño de FPGA, polo tanto, enfatiza os pipelines, as relacións de tempo, a sincronización, a asignación de recursos e o comportamento do dominio de reloxo en vez da orde das instrucións por si soa. Comprender a concorrencia é un dos cambios mentais máis importantes na enxeñaría de FPGA.
6. Por que pequenos cambios en RTL poden de súpeto causar importantes problemas de peche de tempo en proxectos de FPGA?
O comportamento de tempo de FPGA depende en gran medida do colocado, a congestión de roteiro, a difusión, as relacións de reloxo e o uso de recursos físicos. Mesmo pequenas modificacións en RTL poden alterar como as ferramentas de síntese e roteiro mapean a lóxica a través do dispositivo. Un cambio que parece inofensivo pode aumentar a presión do roteiro, alongar os camiños combinacionais ou afectar as decisións de colocado de formas que reduzan significativamenta o margen de tempo. Esta sensibilidade volve máis severa a medida que a utilización aumenta, especialmente cando os deseños se achegan aos límites de roteiro ou reloxeo.
7. Por que os proxectos de FPGA frecuentemente se ven constrinxidos polas realidades a nivel de placa en vez de pola complexidade de RTL só?
A medida que os sistemas de FPGA crecen, os desafíos relacionados co sequenciamento de potencia, a distribución de DDR, a xeración de reloxo, o comportamento térmico, a integridade do sinal e o roteiro do transceptor a miúdo dominan o tempo de desenvolvemento. O RTL pode funcionar correctamente mentres que a infraestrutura de hardware que o rodea introduce inestabilidade ou fallos de integración. Os enxeñeiros a miúdo descobren que as decisións de deseño da placa, o sequenciamento de reinicio e o comportamento da interface de memoria moldean o éxito global do proxecto máis que o HDL en si. Isto é especialmente verdadeiro en sistemas de alta velocidade que usan memoria externa DDR e interfaces SERDES.
8. Por que moitos equipos de FPGA avalían as cadeas de ferramentas tan seriamente como o hardware de FPGA en si?
A cadea de ferramentas FPGA afecta directamente o tempo de compilación, a estabilidade do peche de temporización, a eficiencia na depuración, a integración CI e a produtividade global da enxeñaría. Os resultados de implementación lentos ou inconsistentes poden aumentar dramaticamente o tempo de iteración e a presión do calendario. As equipes adoitan avaliar a calidade da síntese, a clareza do informe de temporización, a instrumentación de depuración e a reproducibilidade antes de comprometerse cunha plataforma. Nos ambientes de desenvolvemento reais, as compilacións predecibles e o peche de temporización estable adoitan importar máis que especificacións de FPGA destacadas illadas.
9. Por que os SoCs Zynq e as plataformas Kria SOM reducen a complexidade de integración en comparación con FPGAs autónomos?
Os SoCs Zynq combinan procesadores ARM e lóxica programable dentro dun único dispositivo, simplificando a comunicación entre o software e a aceleración de hardware. As Kria SOM van máis alá integrando memoria, almacenamento de arranque, secuenciación de potencia e hardware validado nun módulo cualificado previamente. Estas abordaxes reducen os riscos asociados ao roteo DDR, á fiabilidade do arranque, ao deseño de entrega de potencia e á posta en marcha da placa. Como resultado, as equipas poden centrarse máis no comportamento da aplicación e menos nos desafíos de integración de hardware de baixo nivel.
10. Por que a implementación exitosa de IA baseada en FPGA depende moito do movemento de datos en vez do rendemento do acelerador só?
Os aceleradores de IA como os DPU poden proporcionar un alto rendimento teórico de computación, pero o rendemento no mundo real adoita ser limitado pola largura de banda da memoria, a programación DMA, a xestión de buffers e a eficiencia do movemento de tensores. As tubaxes de datos mal optimizadas poden privar ao acelerador e reducir dramaticamente os FPS efectivos a pesar dunha forte capacidade de computación. Por iso, os sistemas de IA baseados en FPGA enfócanse intensamente no double-buffering, na topoloxía DMA, na estratexia de agrupación, na colocación de memoria e no fluxo de datos sostido entre sensores, memoria DDR, aceleradores e fases de post-procesamento.
Blog relacionado
-
Cantos ceros nun millón de millóns de euros?
![Cantos ceros nun millón de millóns de euros?]()
2024/07/29
O millón representa 106, unha figura facilmente comprensiva en comparación con elementos cotiáns ou salarios anuais. Miles de millóns, equivalente... -
Follada de datos Mosfet IRLZ44N, circuíto, equivalente, pinout
![Follada de datos Mosfet IRLZ44N, circuíto, equivalente, pinout]()
2024/08/28
O IRLZ44N é un MOSFET de potencia de canle N moi usado.Coñecido polas súas excelentes capacidades de conmutación, é moi adecuado para numerosas a... -
A temperatura da batería demasiado baixa, a carga parou.Como solucionalo?
![A temperatura da batería demasiado baixa, a carga parou.Como solucionalo?]()
2024/10/6
Os problemas de carga da batería do teléfono móbil son comúns pero pódense xestionar de xeito eficaz.A temperatura xoga un papel importante na ef... -
Guía completa do transistor BC547
![Guía completa do transistor BC547]()
2024/07/4
O transistor BC547 úsase habitualmente nunha variedade de aplicacións electrónicas, que van desde amplificadores de sinal básicos ata circuítos d... -
Guía completa para SCR (rectificador controlado por silicio)
![Guía completa para SCR (rectificador controlado por silicio)]()
2024/04/22
Os rectificadores controlados por silicio (SCR), ou tiristores, xogan un papel fundamental na tecnoloxía de electrónica de poder debido ao seu rende... -
LR621, SR621SW, 364, AG1 Equivalentes e substitucións da batería AG1
![LR621, SR621SW, 364, AG1 Equivalentes e substitucións da batería AG1]()
2024/07/15
As baterías de botóns LR621 e SR621SW prevalecen en dispositivos electrónicos compactos como reloxos, xoguetes pequenos, calculadoras e teclas remo... -
Unha guía completa para os multiplexores e o seu papel nos sistemas dixitais
![Unha guía completa para os multiplexores e o seu papel nos sistemas dixitais]()
2025/09/20
Os multiplexores son compoñentes en sistemas dixitais, deseñados para canalizar múltiples sinais de entrada nunha única liña de saída mediante s... -
Fundamentos dos circuítos op-amplificadores
![Fundamentos dos circuítos op-amplificadores]()
2023/12/28
No complexo mundo da electrónica, unha viaxe aos seus misterios invariablemente lévanos a un caleidoscopio de compoñentes do circuíto, tanto exqui... -
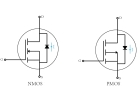
Comparando diferenzas e aplicacións NMOS e PMO
![Comparando diferenzas e aplicacións NMOS e PMO]()
2024/11/15
Comprender as diferenzas entre os transistores NMOS e PMOS é importante no deseño de circuítos eficientes.NMOs (N-Type Metal-óxido-semiconductor) ... -
CR2450 VS CR2032 Comparación: todo o que necesitas saber
![CR2450 VS CR2032 Comparación: todo o que necesitas saber]()
2025/09/15
As baterías de botóns como CR2450 e CR2032 alimentan moitos electrónicos cotiáns, desde reloxos e remotos ata dispositivos médicos e industriais....








Partes quentes
- PIC24FJ128GA306-I/MR
- NJM2871BF33-TE1
- CX25843-23
- LM5110-3M
- GRM1887U1H7R8DZ01D
- GTLP6C817MTC
- ICS8732AY-01LF
- CGB2A3X5R0G105K033BB
- ICX406BQF
- FP6121-KS6PTR
- AD7528JRZ-REEL7
- STR-Y6766
- HMJ212BB7472KGHT
- PIC16LF1513T-I/SS
- 1206AC272KAT1A
- LTC2433-1IMS#TRPBF
- MAX8535EUA
- PM1800HCE1700
- QM150E3Y-HE
- TOP224YN
- GAL22V10-25LNC
- PNX8019DIHNC00
- MT41J128M8JP-125:G
- CEP73A3G
- 2MBI100J-120
- S667223V
- PIC18F4680-E/PT
- RT424024
- SI8435-B-IS
- ADUM131E1BRWZ-RL
- LD051C272KAB4A
- VE-231-MY
- VE-240-CW
- ADG609BR-REEL
- CY7C138-35JI
- EL5002ES
- K9F2G080B-PCB
- M38039G8H-223KP
- PIC16F628A-I
- SRM2B256SLMX70-B
- TMP96C041AFG
- VF2510BGIL
- SAH-XC2361A-72F80LR
- AD42361AJD
- AM29LV008B90EC
- TAP335K016SRS
- MT6255A-B
- TCD41B1DN2
- MKL36Z64VLH
- SWPA6020S1R0NT